今天就开始参考《Python3网络爬虫开发实战》这本书学Python爬虫,第一章就先不写读书笔记了,从第二章开始,以后有机会再补第一章。
urllib库包含的模块
1.request:最基本的http请求模块,可用来模拟请求的发送
2.error:异常处理模块
3.parse:工具模块,提供URL的处理方法
Python官网——urllib.parse 用于解析 URL
4.robotparser:通过识别robots.txt判断可以爬什么
1.发送请求
urlopen
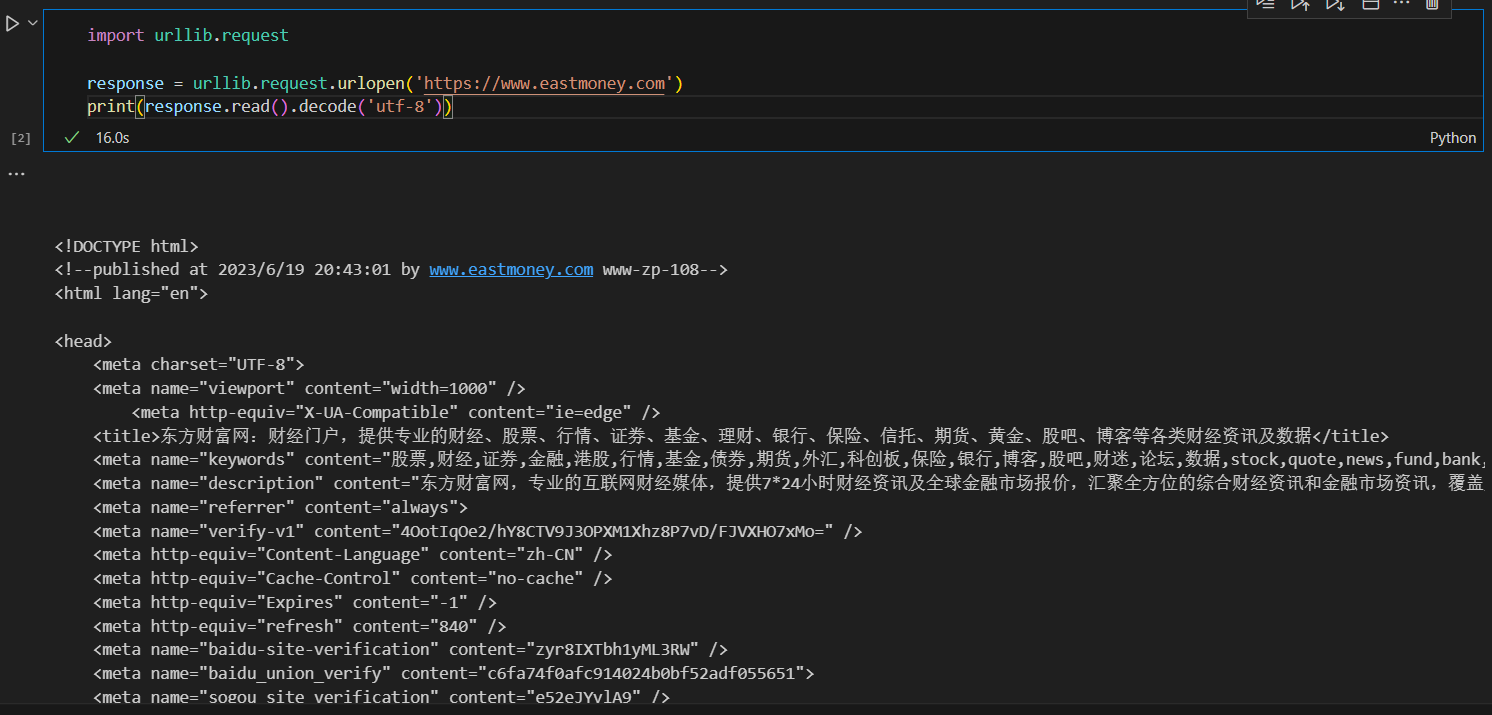
抓取网页
import urllib.request
response = urllib.request.urlopen('https://www.eastmoney.com')
print(response.read().decode('utf-8'))
获取网页部分信息
import urllib.request
# 定义一个函数,用于获取东方财富网页的响应
response = urllib.request.urlopen('https://www.eastmoney.com')
# 将响应的内容解码为utf-8编码
# print(response.read().decode('utf-8'))
# 打印响应类型
print(type(response))
print("----------")
# 打印响应头
print(response.info())
# 打印响应状态码
print(response.getcode())
# 打印响应状态
print("----------")
print(response.status)
# 打印响应头
print("----------")
print(response.getheaders())
# 打印响应头中Server的值
print("----------")
print(response.getheader('Server'))
data参数
data参数不是必选的,添加时需用bytes方法将参数转化为字节流编码格式的内容(bytes类型)
ChatGPT解释:换句话说,如果你想要向服务器发送一些数据,那么你可以将这些数据放到一个Python字典中,然后将该字典通过bytes()方法转换为字节流编码格式的内容,并将其作为data参数的值传递给urllib库中的相关函数。
urllib库中的data参数可以用于向HTTP请求发送数据。这个参数通常是一个字典类型的对象,其中包含了需要传递给服务器的各种数据。但是,由于HTTP协议是基于二进制流传输的,因此需要将字典类型的数据转换为字节流编码格式才能够正确地发送到服务器。
在 Python 中,我们可以使用 urllib.parse 模块中的 urlencode() 方法将字典类型的数据转换为 URL 编码格式的字符串,然后再使用 bytes() 方法将其转换为字节流编码格式的内容。

#data参数
import urllib.parse
import urllib.request
# 将字典转换为url参数
data = bytes(urllib.parse.urlencode({'name':'germey'}),encoding= 'utf-8')
# 发送post请求
response = urllib.request.urlopen('https://www.httpbin.org/post',data=data)
# 获取响应
print(response.read().decode('utf-8'))
timeout参数
用于设置超时时间
其它参数
context参数
必须是ssl.SSLContext类型,用来指定SSL的类型
cafile、capath参数
前者指定CA证书,后者指定其路径
Request
urlopen方法可以发起最基本的请求,但如果要在请求中加入Headers信息则需要Request
书中案例代码:
import urllib.request
request = urllib.request.Request('https://blog.haimianbaibai.cn')
#使用 urllib.request.urlopen() 方法发送请求,并将响应保存在名为 response 的对象中。
response = urllib.request.urlopen(request)
#调用 response.read() 方法读取响应内容,并使用 decode() 方法将字节流解码为 UTF-8 编码的文本。最后将结果打印输出。
print(response.read().decode('utf-8'))但是很明显,这种基本的方法对于毫无防范的网站还行,但稍微有点waf、或者网站管理员想管你的情况下就不行了,比方说本站就有一些基本的反爬规则,使用以上代码爬取本站则就出现403的情况。

使用urlopen方法发送请求,参数是一个request类型的对象,可以把请求独立成一个对象,且能更丰富和灵活的配置参数。
Request类构造方法:class urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
- url:用于请求URL,必传参数
- data:若要传数据,则必须传bytes类型。若 数据是字典,则先用
urllib.parse里的urlencode方法进行编码。 headers是一个字典,这就是请求头。构造请求时可直接构造,亦可通过调用请求示例的add_header方法添加。
- 通过修改User-Agent伪装浏览器。如我的ua:
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/114.0",
- 通过修改User-Agent伪装浏览器。如我的ua:
- origin_req_host:请求方的host名或IP地址
unverifiable:表示请求是否是无法验证的,默认值是False,意思是用户没有足够的权限来接受这个请求的结果。
- 例:请求文档中的图片但没有抓图像的权限,unverifiable就是True
method:一个字符串,用来指示请求使用的方法
GETPOSTPUT
这样我们再来构造一个Request类试一下
from urllib import request,parse
url = 'https://blog.haimianbaibai.cn'
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/114.0",
'Host': 'blog.haimianbaibai.cn'
}
dict = {'name': 'hmbb'}
data = bytes(parse.urlencode(dict), encoding="utf-8")
req = request.Request(url, data=data, headers=headers,method='POST')
response = request.urlopen(req)
print(response.read().decode('utf-8'))
这次加了UA的伪装就很轻松的爬到了
不过既然我们要学习,还是要跟着书上看一下,用那个网址观察我们构造的这个函数都成功设置了什么
from urllib import request,parse
url = 'https://www.httpbin.org/post'
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/114.0",
'Host': 'www.httpbin.org'
}
dict = {'name': 'hmbb'}
data = bytes(parse.urlencode(dict), encoding="utf-8")
req = request.Request(url, data=data, headers=headers,method='POST')
response = request.urlopen(req)
print(response.read().decode('utf-8'))
高级用法——Handler
BaseHandler类
urllib.request模块里的BaseHandler类是其他所有Handler类的父类,他提供了最基本的方法。
会有各种Handler子类继承BaseHandler类。
- HTTPDefaultErrorHandler:处理HTTP相应错误,所有错误都会抛出HTTPError异常
- HTTPRedirectHandler:处理重定向
- HTTPCookieProcessor:处理Cookie
- ProxyHandler:设置代理
- HTTPPasswordMgr:管理密码
- HTTPBasicAuthHandler:如果链接打开时要认证,用这个
OpenerDirector类(简称Opener)
Opener可以实现更高级的功能,可以深入一层进行配置,使用更底层的实例完成操作。
opener类可以提供open方法,可以利用Handler类构建Opener类
验证
from urllib.request import HTTPPasswordMgrWithDefaultRealm,HTTPBasicAuthHandler,build_opener
from urllib.error import URLError
# 定义用户名和密码
username = 'admin'
password = 'admin'
# 定义url
url = 'https://ssr3.scrape.center'
# 创建一个HTTPPasswordMgrWithDefaultRealm类的实例
p = HTTPPasswordMgrWithDefaultRealm()
# 将用户名和密码添加到HTTPPasswordMgrWithDefaultRealm类的实例中
p.add_password(None, url, username, password)
# 创建一个HTTPBasicAuthHandler类的实例
auth_handler = HTTPBasicAuthHandler(p)
# 创建一个opener实例
opener = build_opener(auth_handler)
try:
# 使用opener实例打开url
result = opener.open(url)
# 使用result.read()获取url的响应内容
html = result.read().decode('utf-8')
# 打印url的响应内容
print(html)
except URLError as e:
# 如果发生URLError异常,打印异常信息
print(f"Something went wrong: {e.reason}")
代理
示例代码:
from urllib.request import ProxyHandler,build_opener,HTTPSHandler
from urllib.error import URLError
# 定义代理模式,指定代理地址和端口号
proxy = ProxyHandler({
'http':'http://127.0.0.1:36545',
'https':'http://127.0.0.1:36545'
})
# 创建opener对象,添加代理模式
# HTTPSHandler(context=ssl._create_unverified_context())用来忽略ssl证书错误
opener = build_opener(proxy,HTTPSHandler(context=ssl._create_unverified_context()))
try:
# 打开url,获取响应
response = opener.open('https://myip.ipip.net')
# 获取响应内容,并解码为utf-8编码
print(response.read().decode('utf-8'))
except URLError as err:
# 如果出现URLError异常,打印错误信息
print(err.reason)
成功
Cookie
- 获取网站Cookie
首先声明一个CookieJar对象,然后利用HTTPCookieProcessor构建一个Handler,最后利用build_opener方法构建Opener,执行open
#Cookie
#Cookie
import http.cookiejar,urllib.request
#创建CookieJar实例
cookie = http.cookiejar.CookieJar()
#创建HTTPCookieProcessor实例
handler = urllib.request.HTTPCookieProcessor(cookie)
#创建opener实例
opener = urllib.request.build_opener(handler)
#使用opener发送请求
response = opener.open('https://www.baidu.com')
#遍历cookie
for item in cookie: print(item.name + '=' + item.value)
以文本形式保存Cookie
#以文本形式保存Cookie import urllib.request,http.cookiejar filename = 'cookie.txt' # 创建一个MozillaCookieJar实例 cookie = http.cookiejar.MozillaCookieJar(filename) # 使用HTTPCookieProcessor创建一个cookie处理器 handler = urllib.request.HTTPCookieProcessor(cookie) # 使用build_opener方法创建一个opener opener = urllib.request.build_opener(handler) # 使用opener.open方法打开一个url response = opener.open('https://www.baidu.com') # 保存cookie到cookie.txt文件中 cookie.save(ignore_discard=True,ignore_expires=True)
用LWPCookieJar保存为LWP格式的Cookie
import urllib.request,http.cookiejar filename = 'cookie.txt' cookie = http.cookiejar.LWPCookieJar(filename) #仅需修改此处 # 使用HTTPCookieProcessor创建一个cookie处理器 handler = urllib.request.HTTPCookieProcessor(cookie) # 使用build_opener方法创建一个opener opener = urllib.request.build_opener(handler) # 使用opener.open方法打开一个url response = opener.open('https://www.baidu.com') # 保存cookie到cookie.txt文件中 cookie.save(ignore_discard=True,ignore_expires=True)
读取LWPCookieJar格式的Cookie
import urllib.request,http.cookiejar # 创建一个LWPCookieJar实例 cookie = http.cookiejar.LWPCookieJar() # 加载cookie.txt文件,忽略排除的discard和expires cookie.load('cookie.txt',ignore_discard=True,ignore_expires=True) # 创建一个HTTPCookieProcessor实例 handler = urllib.request.HTTPCookieProcessor # 创建一个opener实例,并将HTTPCookieProcessor实例作为参数传入 opener = urllib.request.build_opener(handler) # 使用opener实例打开百度页面 response = opener.open('https://www.baidu.com') # 输出百度页面的内容 print(response.read().decode('utf-8'))
注:在本段代码中handler的作用:

再度复习handler有什么作用(由GPT总结)
在Python爬虫中,Handler是用于处理URL打开请求的模块。它可以对请求进行一些额外的处理,比如添加headers、设置代理等操作,以便让我们的爬虫程序更加灵活和高效。
Python标准库中提供了多种Handler,常见的有以下几种:
- ProxyHandler:用于设置代理。
- HTTPBasicAuthHandler:用于处理HTTP基本认证。
- HTTPCookieProcessor:用于自动处理HTTP Cookie信息。
- HTTPSHandler:用于处理HTTPS请求。
- HTTPRedirectHandler:用于处理HTTP重定向。
使用Handler可以辅助我们编写更加高级的爬虫程序,例如:
- 设置代理服务器,防止被目标网站封IP。
- 处理HTTP认证,让爬虫可以获取需要认证才能访问的页面。
- 处理HTTP重定向,跳转到正确的页面并获取内容。
- 自动管理cookie,维持登录状态。
拓展阅读:
了解更多关于Handler的知识,可以查看Python官方文档:https://docs.python.org/3/library/urllib.request.html#urllib.request.OpenerDirector.add_handler
处理异常
urllib库中的error模块定义了由request模块产生的异常。当出现问题时,request模块便会抛出error 模块中定义的异常。